
Revisiting Postgres -2
Continuing on the usage of Indexes

So last time, this is where we left off. A table was created. Fetches were made. Timing was measured. An index was added.
No difference observed. If you missed it, here it is for a quick recap -
Revisiting Postgres -1

In college, we were taught about MySQL. It was in fact, the First Database I ever even tried. Since then, I’ve tried using a lot of databases, but MySQL holds a special place in my mind, simply because it was the First one I learnt about. So for that reason, I even seem to have conflated it as one of the earliest databases to have been created.
Now, what I’ve done is written up a code snippet to keep adding 100 rows at a time upto a certain number of rows I want to have in the ‘sales’ table and for every 100 rows, perform the fetch operation and measure the time taken to monitor the increase in time .
For reference, the query in question being measured was -
SELECT COUNT(*) FROM sales WHERE sale_location = 'Hyderabad';
Here’s the snippet -
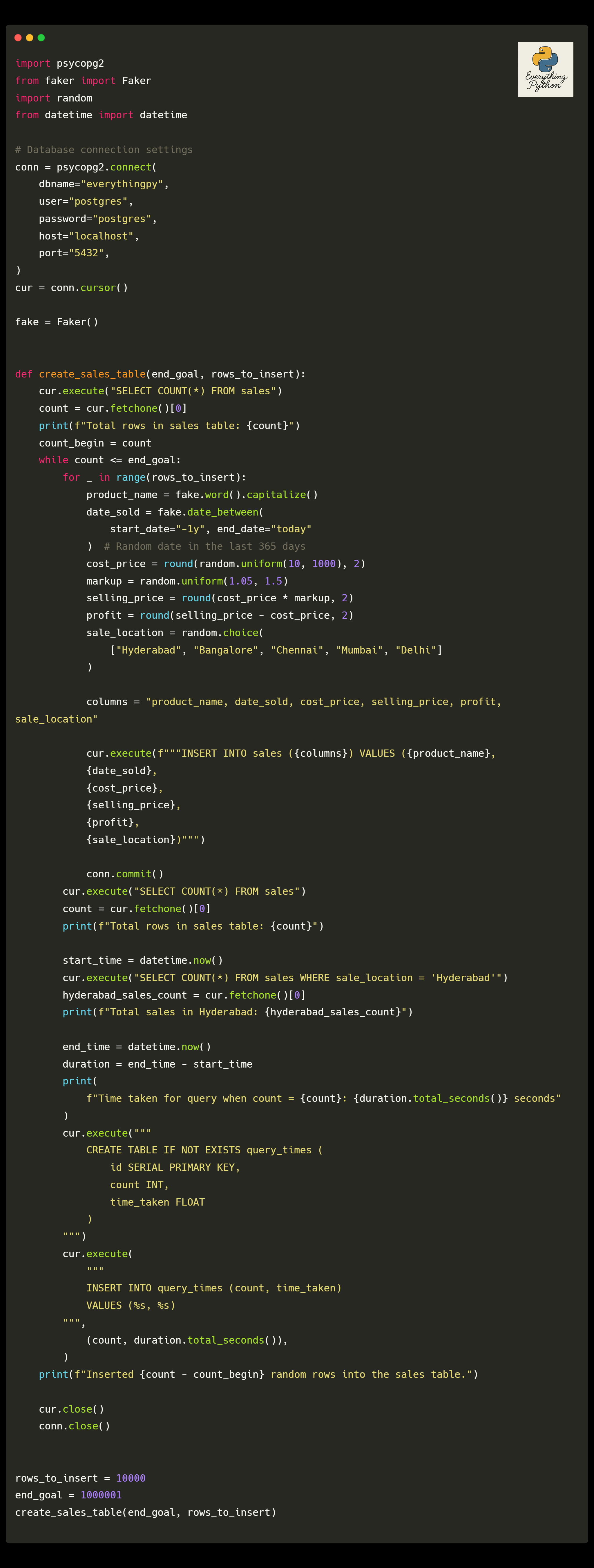
I started the initial “end_goal” as 5000 records and this went on for a while. I kept pushing the goal post and measured the time over and over again.
This is part of what the results looked like over intervals -
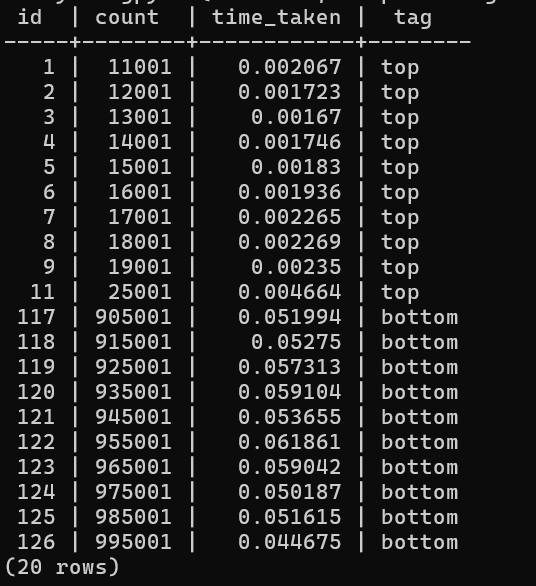
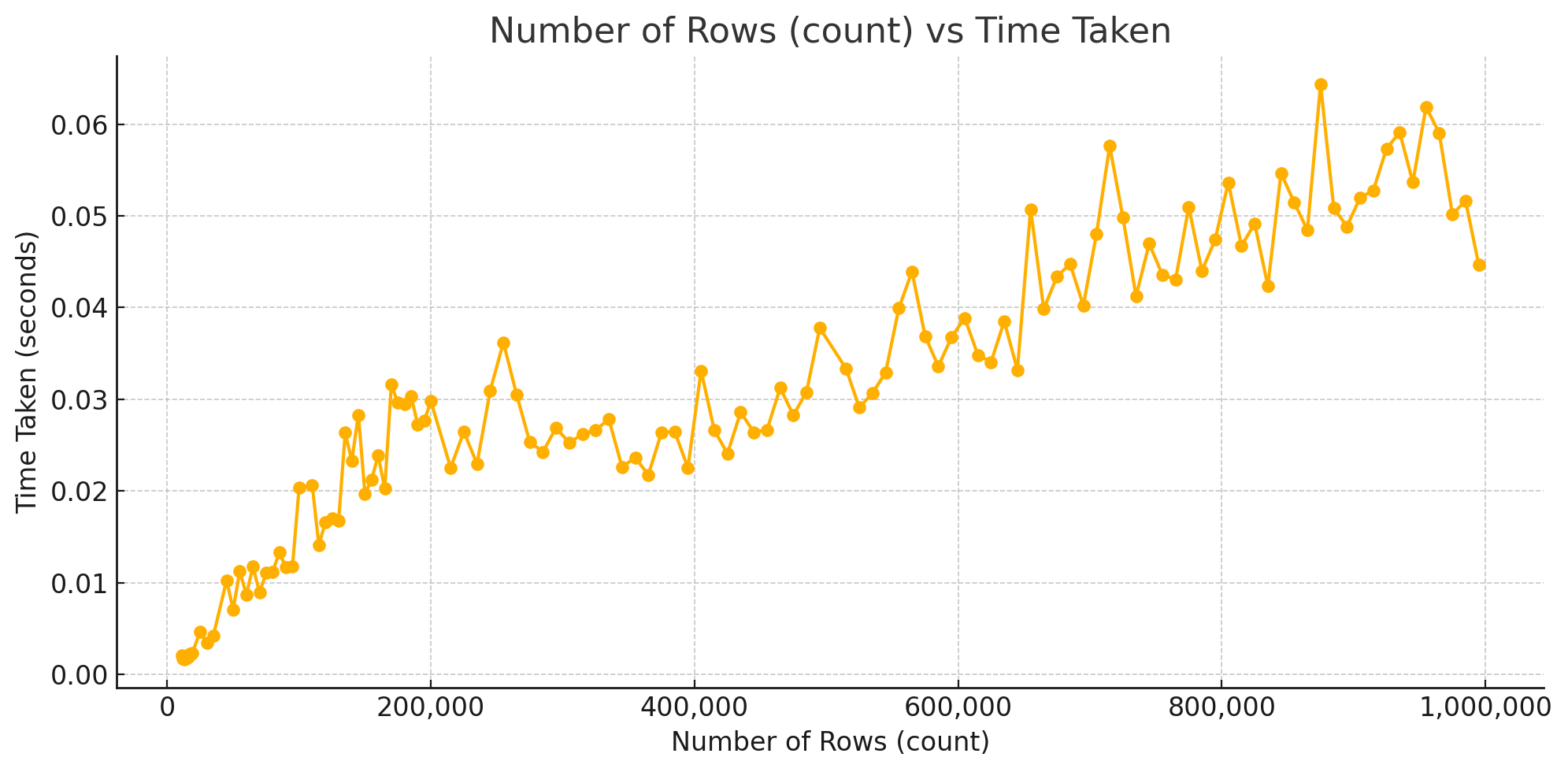
So the time taken is steadily growing with the number of rows being added in the dataset as expected.
So if I compare at the 1M row level, the time taken to fetch the results for the query above with and without an index, I Should see a marked difference in the time taken.
The following video shows this effect -
But if you don’t want to go through it, here’s a quick peek -
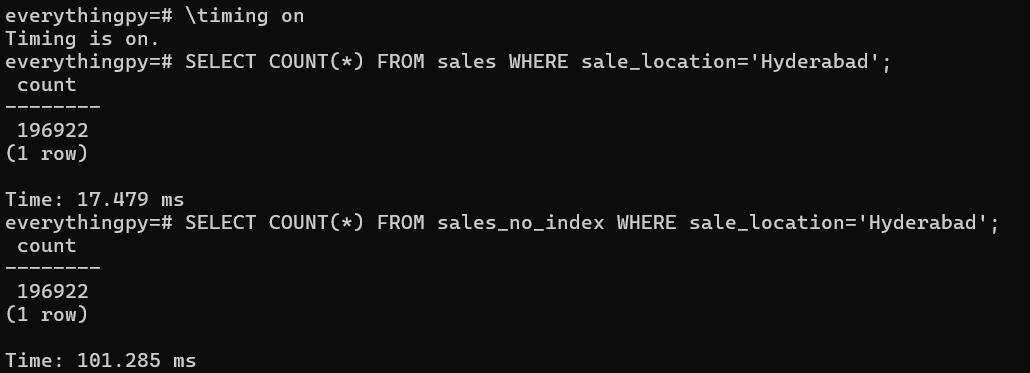
I’d created two tables, one on which I created an Index - ‘sales’ and one on which I hadn’t, very creatively named…. ‘sales_no_index’.
As we can see, the table on which the index is applied was scanned a lot quicker - almost 6x faster in this case. But where is the proof that the index was actually used?
Enter - the EXPLAIN keyword.
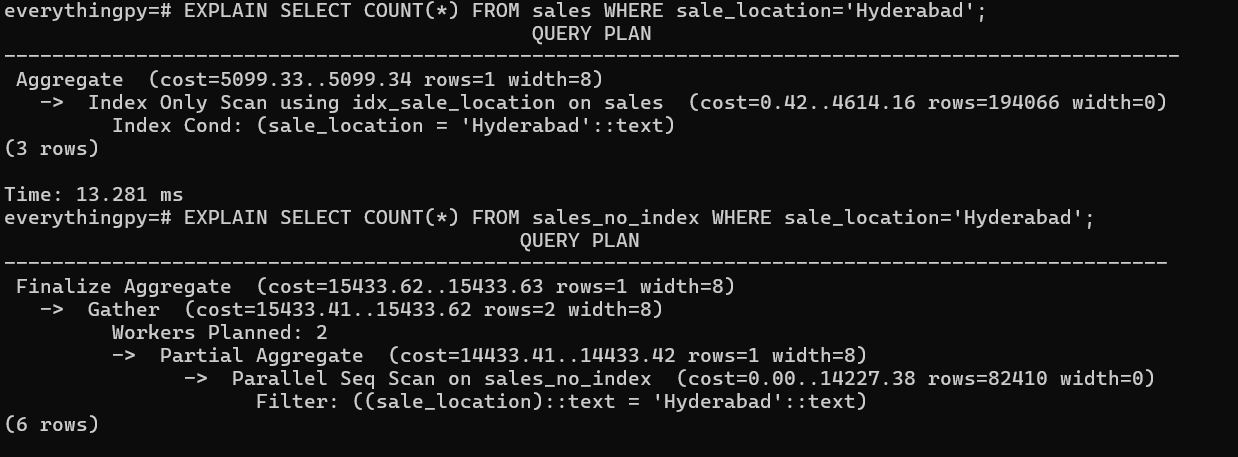
When we ask for the 2 SELECT statements to be EXPLAIN-ed, we can see that the first statement explicitly uses the idx_sale_location Index to fetch rows with sale_location=’Hyderabad’ whereas the second statement executes a Parallel Sequential Scan which takes more time.
But is this proof enough? Where do indexes not make a difference? Is size of data the only criteria? And what’s happening under the hood?
I would like to see more. I will explore this in the next edition of EverythingPython..err..EverythingPostgres.
Thanks for reading this edition of Everything Python! Subscribe for free to receive new posts and support my work.
Also check out my Youtube channel from above and Subscribe. I hope to create more videos on all things Engineering - From coding in Python to Databases and GenAI !