

One of the most sought after things to learn right now is about how to set up your own local LLM server and how to use LLM models locally. With the arrival of some things like Ollama and LM Studio etc, it has become very easy. Ollama is an orchestrator that lets you serve up models locally, models like Llama 3.1, Qwen-2.5, Phi, whatever models you have on HuggingFace. These are available to be served up and many more.
Why would I want to do this?
Fair question to ask in the face of so many ubiquitous LLM offerings present like ChatGPT, Claude, Gemini etc. Why do I even want to set up an LLM locally? I asked ChatGPT this and it told me a lot of what I was thinking along the lines of - like privacy, to prevent reliance on possibly unreliable internet and it kept going for a while, so I asked it to -

Setting up Ollama -
Depending on your operating system, download the corresponding Ollama executable from the official website.
Once you download and run it, it should be running as a small service in the background of your operating system. For example, if you're on Windows, you should be able to see it running on the tray on your screen's bottom right corner.
If you’re on a Mac, it should show up on your Menu bar like so -

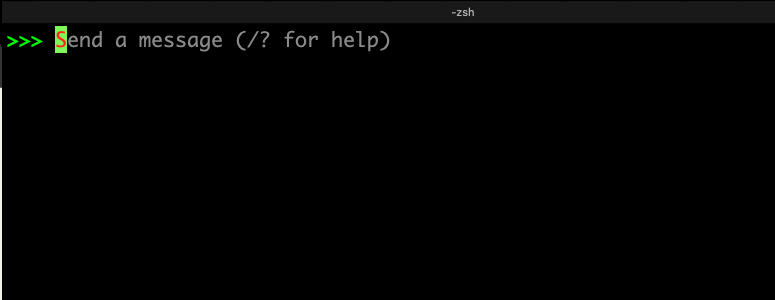
To test that it’s working, open up a CMD or a Terminal instance and type :
ollama -h
To download any existing models, fetch them from the Ollama Models page and pull them locally using
ollama runFor example, I want to run one of the latest models - olmo2
Once that model is pulled, the prompt looks a little like this -

Smaller models are better for lower config laptops/desktops.


This section is optional.
The next thing to do to mimic a local Chat-GPT-ish experience is to hook this backend Ollama server to a front-end web interface. This is where https://openwebui.com/ comes in.
Setting up OpenWebUI -
The Github README for OpenWebUI is extremely helpful. A few months ago when I tried it out, they only had the Docker based offering but now it seems that all that is to be done to set it up is -
uv pip install open-webuiopen-webui serve
So when you visit localhost:8000 on your browser you should be able to see a chatgpt-ish interface and the list of models you downloaded on Ollama on a top-left corner dropdown.
Performance
"How fast is it?", a friend asked. It's not going to be comparable to OpenAI/Claude/Gemini server speeds given that it is limited by your local laptop's CPU/GPU. But on a Mac M1 or a Windows i5 with 32 GB RAM, it's able to run and engage in processing and conversations at fairly decent, tolerable speeds.
What are my other options?
There's a couple of other options like LMStudio and Msty, but those are "left as an exercise to the reader" to try out. :D
Happy local chatting!
If you found this useful, please share it with your friends and ask them to subscribe to EverythingPython as well!