

This entire post is being conducted in the context of the Windows OS .
This can be tried on Ubuntu with minimal effort. I just purged my entire WSL setup because it was taking a lot of space.
For the last year or so, the entire developer world has been trying out all sorts of Generative AI experiments - some in the comfort of their own laptops, some on managed services like Together AI etc. and some on Enterprise like Azure, Google and Amazon. The models that have ended up under use have been pretrained on a few million tokens to billions of tokens. Now when we use these models, the most common being OpenAI, there is a way to check the limits and usage on OpenAI’s website . But now with the advent of local models, Claude, Gemini, Phi and so, so many models (There’s a full list here - https://github.com/Hannibal046/Awesome-LLM) , it’s getting harder and harder to track our usage of said models.
That’s why I set out looking for a library that does this and found a few of them.
Initially I tried out measuring my calls using MLFlow. And it works of course but I was using an older version of MLFlow at the time of writing this article and setting up parameters by myself to track the LLM metrics I want to track was tedious. I think when I was looking up the link to add it to this article, they’ve probably made it easier? I don’t know. I will try it out later.
For now, I’ve tried out LiteLLM and OpenLite to measure how many tokens my OpenAI calls take and how much they cost. And here is the process and the results -
🧪How to Use LiteLLM
Clone the litellm package
Setup docker first if necessary. Docker desktop is free if you're an individual using it for small projects.
Assuming you're using OpenAI APIs in this article.
For LiteLLM, the following environment variables are required to be set -
LITELLM_MASTER_KEY - The value for this can be anything. I'm using "sk-1234"
DATABASE_URL - This gave me a LOOOOT of trouble to figure out. The final value I used is "
postgresql://abhi:abhi@localhost:6543/llmlite"
Setup a local postgres docker container. (Steps in earlier article below 1 )
Create a virtual env on CMD with >= python3.11
Install the requirements in the requirements.txt file
Activate the virtual env and start the llmlite service as follows -
D:\Github\litellm>litellmLogin to the LLMLite dashboard at
http://localhost:4000/and access the UIAdd your first model with the secret key and model etc. in the models section -


Create a new LLMLite API key in the Virtual keys section
Use the key as follows in the example code to call LLM -

The API calls can then be observed to be tracked on the LLMLite dashboard as follows . Access it at http://localhost:4000




The different tabs are a trip in themselves. The main tab I found of use was well, the usage tab. It tracks the models being used and how many calls were made etc. The catch here is that if I want to see All the models being used, I have to pay a small amount per month or annually.
Now let’s look at an alternative -
🧪How to use Openlit
Clone the OpenLit repo.
Create a new virtual env , say openlit_env using the requirements file in my code repository.
Activate it and install the
openlitpackage along withopenaiand any other packages needed for your codeIn the openlit folder, run the
docker compose upcommandopenlituses the Clickhouse database to store metrics, unlike Litellm that uses Postgres in the example.
In the code that you want to measure metrics in, prefix just these 2 lines -
import openlit
openlit.init( otlp_endpoint="http://127.0.0.1:4318", )So the net code looks like this -
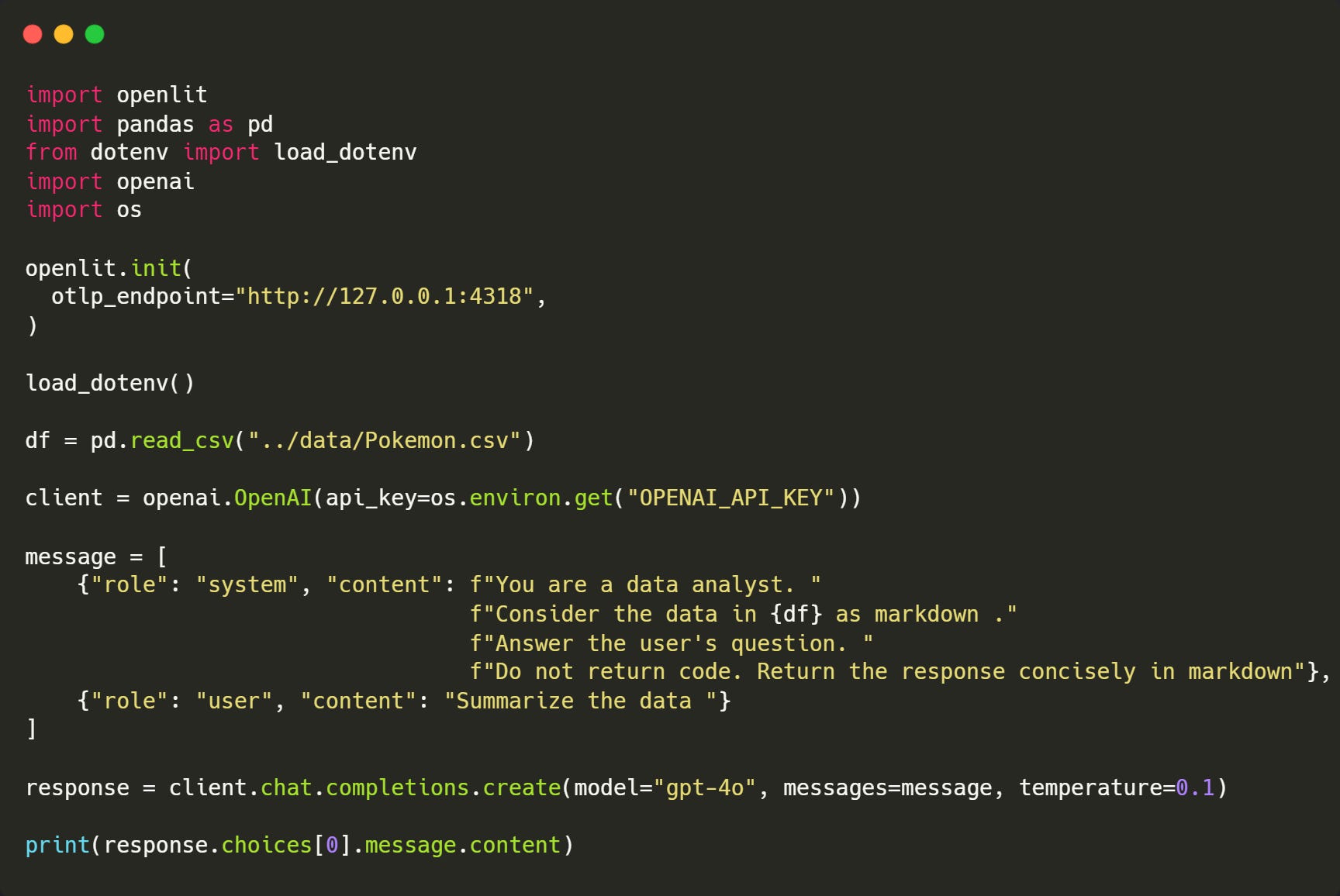
Now if you access your Openlite dashboard at 127.0.0.1:3000, this is how the tracked metrics look like -
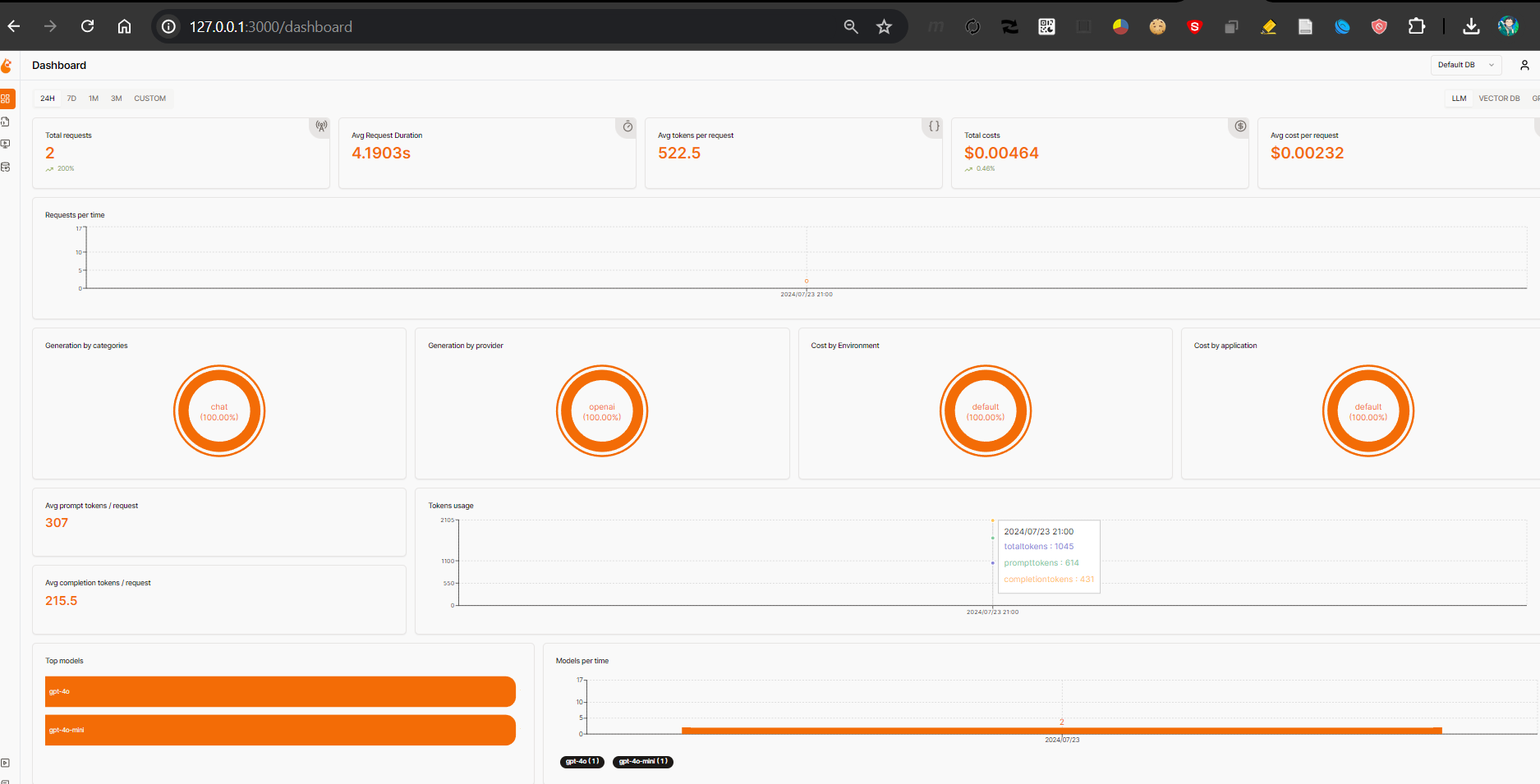
Just to see if it gets updated if the model changes, let’s try out another piece of code , this time running llama3.1-8b locally (a subject for a later post),

And it totally works -

The tabs in Openlit are admittedly fewer, but every bit of info that is tracked is Extremely useful . For example, in the following entry, the request time, the duration of the call, the model under use, the Type of API call etc. Everything tracked is useful and transparent.
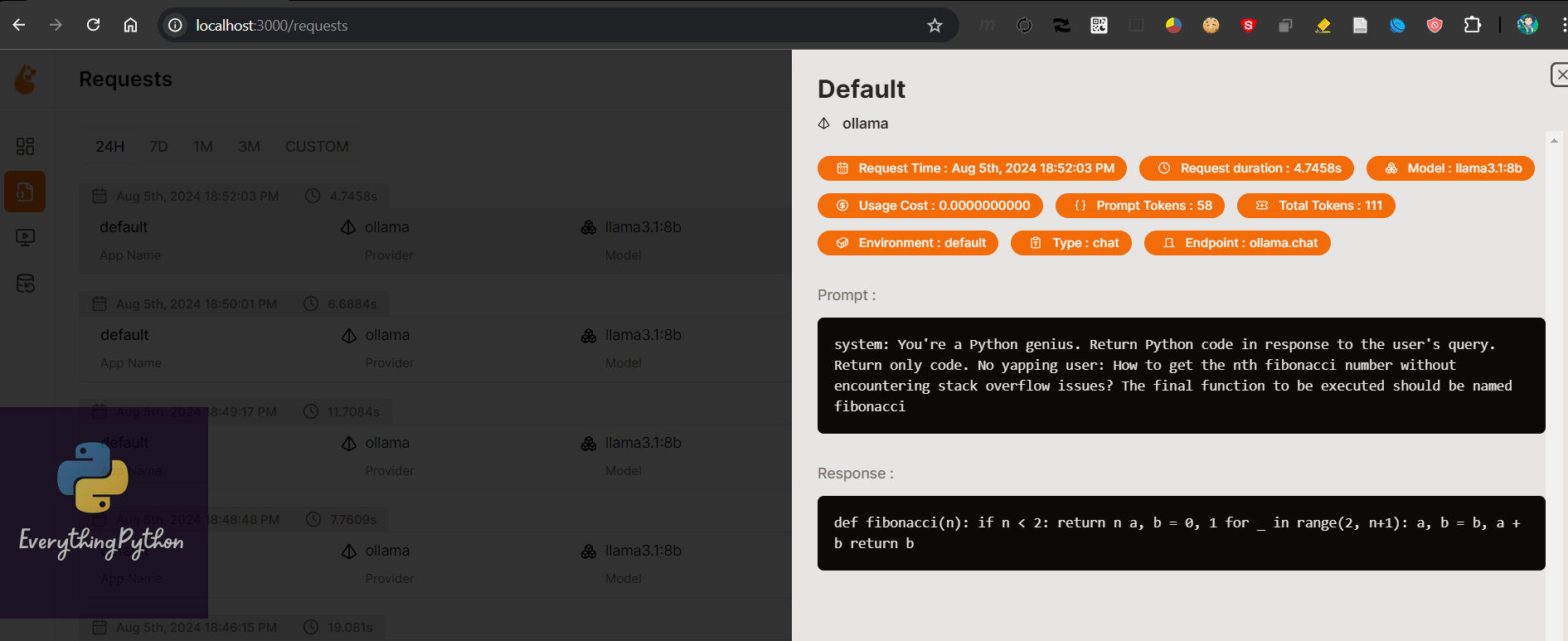
All the code used in this post has been uploaded here - https://github.com/everythingpython/posts/tree/main/2024_08_06_openlit
References -
https://open.substack.com/pub/shinoj1/p/python-development-with-pymvvm-simplifying?r=4auyjk&utm_medium=ios